What is Mintlify?
Mintlify is a modern documentation management platform that has rapidly gained traction among fast-growing companies and startups. With over 10,000 companies now using the platform, including an impressive 20% of the most recent Y Combinator batch, Mintlify has established itself as a go-to solution for teams looking to create beautiful, functional documentation.
Requirements
These requirements are based on available public information, assumptions, and common patterns for documentation platforms like Mintlify. Exact figures may vary in production, but this gives us a foundation to work from.. based on information I can Infer, and conversations that I have had with the team
Functional Requirements
Documentation Hosting – Must serve developer documentation pages (Markdown-based, MDX) with fast load times.
-
WYSIWYG + Code Editor – Allow authors to create, edit, and preview docs in a live editor.
-
Search – Provide instant search with keyword highlighting across all documentation content. (Using RAG)
-
Versioning – Support multiple versions of docs for different product releases.
-
Theming & Customization – Let teams customize branding, colors, and layouts.
-
Analytics – Track page views, search terms, and reader engagement.
Non-Functional Requirements
-
Performance – Pages should load in under 200 ms for 95% of users globally.
-
Scalability – Handle spikes when product launches or API updates drop. e.g., 10× normal traffic in one day (Like OpenAI oss-gpt drop for example).
-
Reliability – 99.9% uptime target.
-
SEO Optimization – Static pre-rendering for fast indexing by search engines.
-
First Contentful Paint (FCP): ≤ 1.8 seconds (Google’s “good” threshold)
-
Largest Contentful Paint (LCP): ≤ 2.5 seconds (Google’s “good” threshold)
-
Time to Interactive (TTI): ≤ 3 seconds
-
Global p95 (95th percentile load time): ~ 2–3 seconds for a content-heavy documentation site
Looking at a well known company that uses them, Bland AI we can check for metrics on load speeds
Figure 0: Blands Documentation Metrics
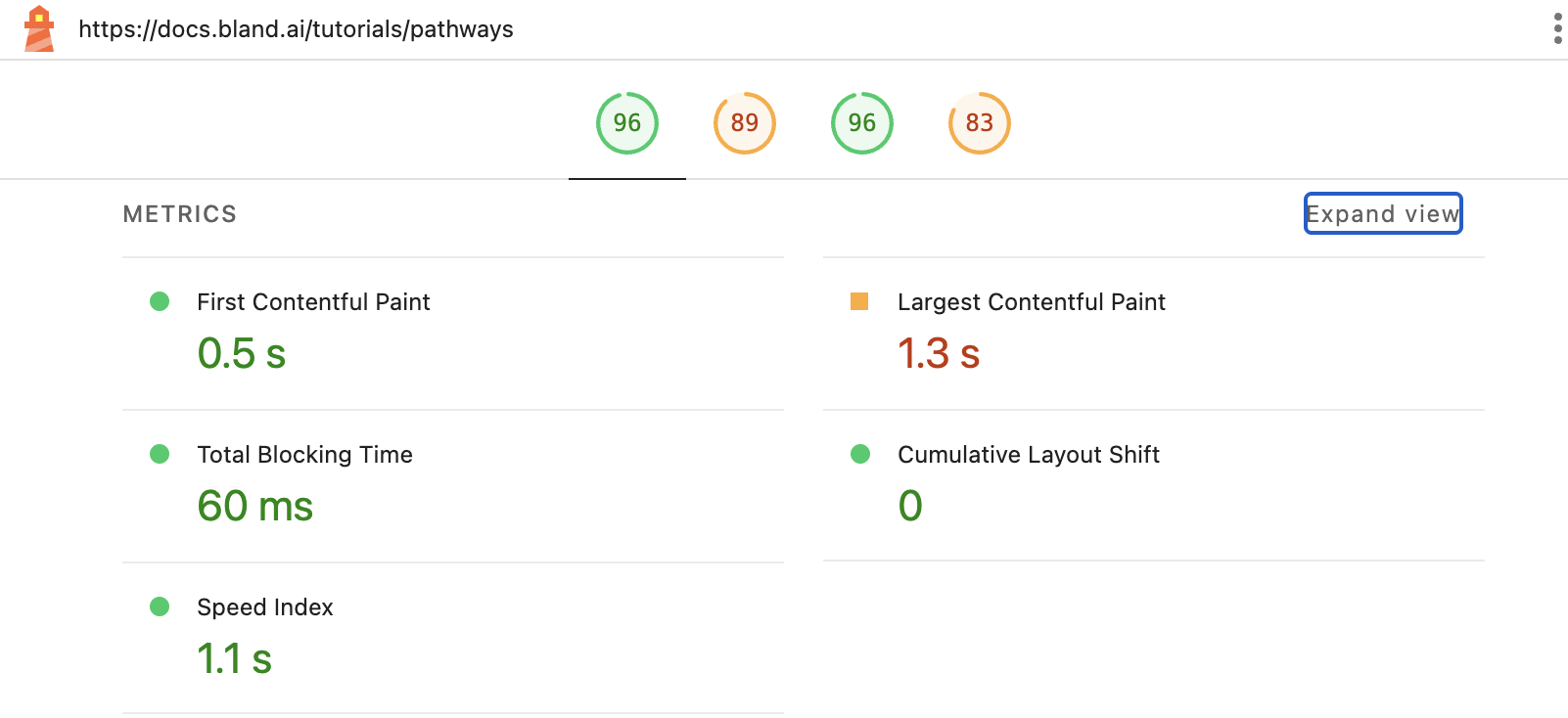
Back-of-the-Napkin Estimates
Mintlify states in their job posting Here that "100M+ developers/year" and “10,000+ companies”, use their platform… here’s a rough breakdown:
Traffic
Annual: ~100,000,000 unique developers/year.
Monthly active readers: ~8,300,000 (100M ÷ 12).
Assuming each developer views ~5 pages per visit: → ~41,500,000 page views/month.
Peak load estimate (10× spike during major launches): → ~4,150 requests/sec at extreme peak. → Baseline: ~415 requests/sec average.
Storage
Avg doc site size (text, media, assets): ~50 MB. → 10,000 companies × 50 MB ≈ 500 GB raw content.
With versioning and backups (×3): ≈ 1.5 TB.
Search Index Assuming ~10 MB index per company: → 10,000 companies × 10 MB = 100 GB search index.
Analytics Data Page view logs: ~200 bytes/request × 41.5M views = ~8 GB/month raw logs.
With processing, rollups, and retention (18 months): ≈ 150 GB.
Mintlify Database
Mintlify is a read-heavy documentation platform. Put another way, the typical usage pattern is developers reading documentation pages across multiple companies and versions. Not a whole lot of writng to the DB going on.
Defining Data model
Here is a super light schema possibility for the data model they are using
Company: company_id, name, plan_type, created_at
User: company_id, name, email, created_at
Documentation: doc_id, company_id, version, path, title, content_markdown, content_html, content_embedding
Analytics: event_id, company_id, event_type, metadata, created_at
Database Schema The major entities of the relational data schema for Mintlify are shown in Figure 1.
Figure 1: Mintlify Database schema
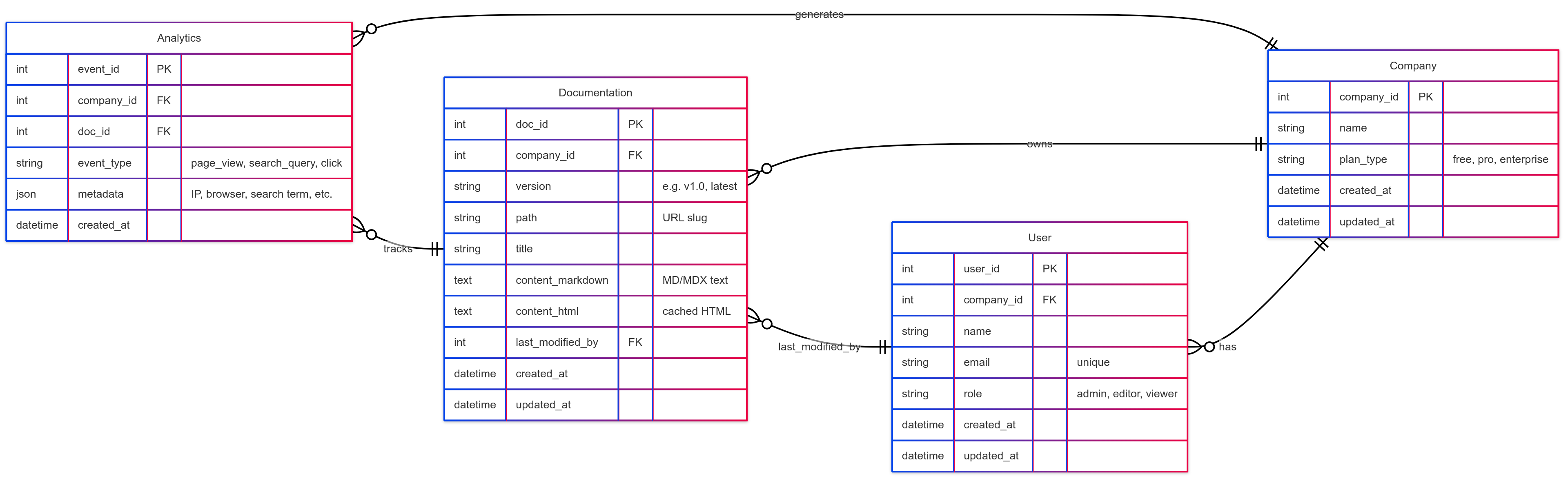
PostgreSQL supports JSONB data type columns in the relational table. The documentation table can be used to persist the theme configurations and metadata in a JSONB data type column instead of generating dedicated configuration tables. The write-behind cache pattern can be enforced to store the frequently accessed docs with high performance and low latency.
A shared documentation site is similar to a normal company documentation but acts as a connecting bridge between multiple organizations. A single copy of the shared documentation data should be persisted and the data access requests must be routed to the database shard hosting the company for scalability and performance. The shared_docs table can be used to bridge the companies in a shared documentation space.
Query to fetch the recent 20 documentation pages:
SELECT doc_id, title, path, version, updated_at, metadata
FROM documentation
WHERE company_id = $1
ORDER BY updated_at DESC
LIMIT 20;Semantic search query using pgvector:
-- Find similar documents using vector similarity
SELECT
doc_id,
title,
path,
1 - (content_embedding <=> $1::vector) AS similarity_score
FROM documentation
WHERE company_id = $2
ORDER BY content_embedding <=> $1::vector
LIMIT 10;The database index can be initialized to read the documentation pages with low latency at the expense of increased storage and elevated latency on write operations.
Type of Database
PostgreSQL is the optimal choice for building the data storage layer for Mintlify due to the following reasons:
- Superior full-text search capabilities using built-in text search features and GIN indexes
- Native vector embedding support with pgvector extension for AI-powered semantic search
- Excellent performance with read-heavy workloads through read replicas and connection pooling
- JSONB support for flexible metadata storage with efficient querying
- Robust indexing strategies including B-tree, GIN, and IVFFlat indexes for different use cases
- Strong consistency with configurable replication for high availability
The PostgreSQL database should be configured with read replicas to handle the read-heavy traffic patterns while maintaining write performance on the primary instance.
Storage Strategy
- Relational DB: Stores MDX content, version history, and metadata.
- Object Storage (S3/GCS): Stores images, PDFs, and static assets, served via CDN.
- Content Hashing: Used to deduplicate and invalidate CDN caches on updates.
Mintlify Architecture
Prototyping
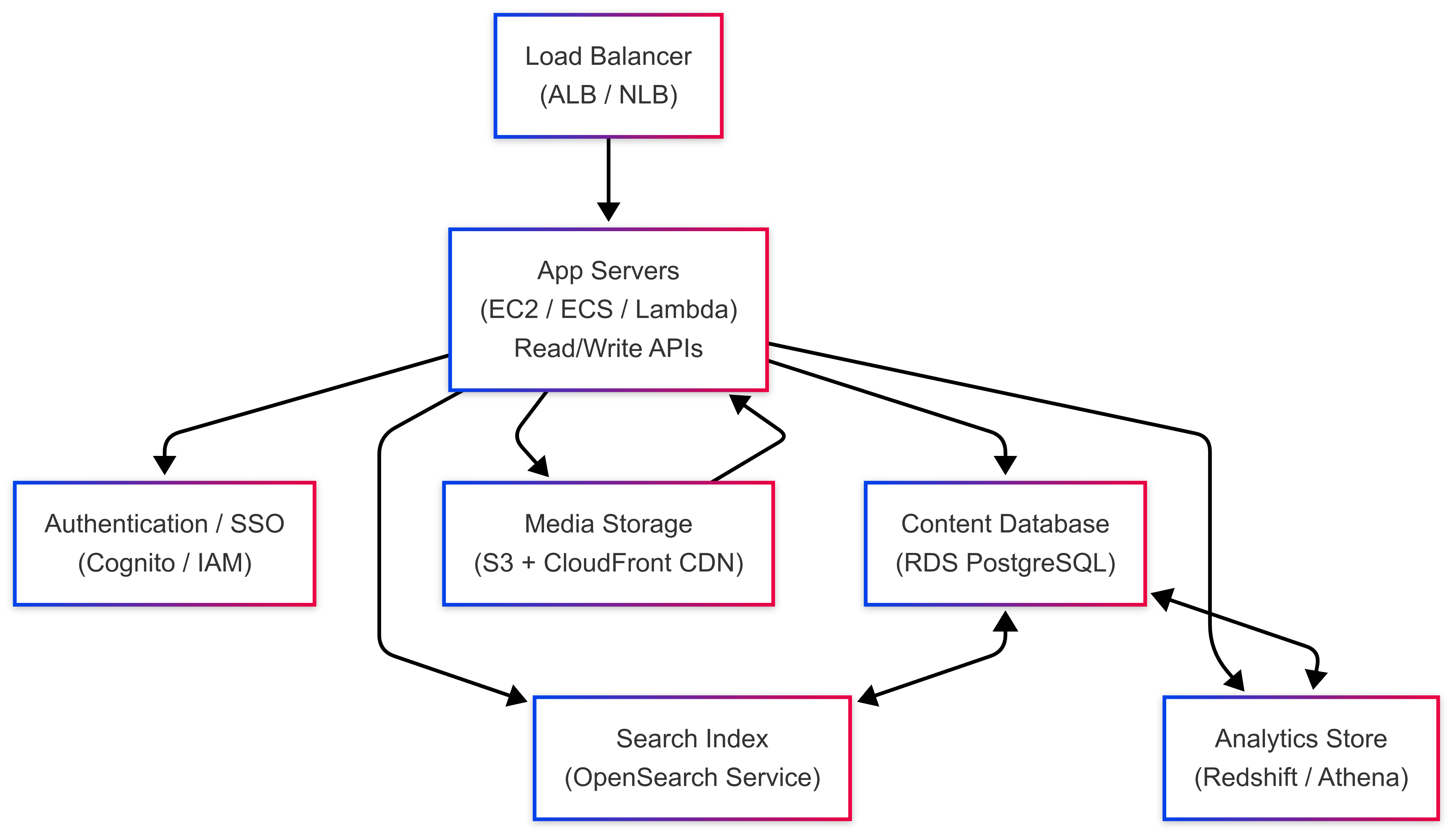
Here is a high-level block diagram that covers everything from content creation → hosting → reading → analytics.
Load Balancer – Distributes incoming requests to the right application servers.
App Servers – Serve documentation pages, process edits, manage API calls, and integrate with search/analytics.
Authentication/SSO Service – Handles login with GitHub, Google, or email for editors/admins.
Content Database – Stores docs, versions, company data, and user accounts.
Media Storage – Stores images, PDFs, and assets used in documentation (served via CDN).
Analytics Store – Stores page views, search queries, and engagement metrics for dashboards.
Figure 2: Mintlify MVP Architecture
Search Architecture
Mintlify combines:
- Keyword Search: OpenSearch for classic keyword and faceted search.
- Semantic Search: pgvector (PostgreSQL extension) for embedding-based similarity.
Index Updates:
- Triggered on document creation/update events.
- Batched background workers handle large re-index jobs to keep search fresh without blocking writes.
Scaling And Reliability
Tenant Isolation Strategies:
Code Level: Middleware-based routing by subdomain/domain
Data Level: Organization-based partitioning
Performance Level: Per-tenant caching and rate limiting
Horizontal Scaling
Stateless Services: All application services are stateless for easy scaling
Database Scaling: Read replicas and connection pooling
CDN Optimization: Vercel's global edge network with automatic caching
Auto-scaling: Serverless functions scale automatically with demand
Analytics Pipeline
- Ingestion: Events streamed into Kafka for durability.
- Processing: Aggregated in ClickHouse for fast dashboard queries.
- Archival: Raw logs moved to S3 Glacier for long-term storage and compliance.
Reliability Patterns
Circuit Breaker: Prevent cascading failures in AI services
Retry Logic: Exponential backoff for external API calls
Graceful Degradation: Fallback to static content when dynamic features fail
Health Checks: Continuous monitoring of service endpoints
Global Reliability Enhancements
- CDN Edge Fallback: Serve last-known-good ISR pages when origin is down.
- Cold Start Mitigation: Pre-warm critical serverless functions during known peak traffic.
- Rate Limiting: Per-tenant and per-IP limits to protect AI endpoints from abuse.
Load Balancing Strategy
Geographic Routing: Traffic routed to nearest edge location
Weighted Routing: Gradual rollouts of new features
Failover: Automatic failover to backup regions
Advanced Features
AI-Powered Search and Chat
Architecture Components:
Content Indexing: Automatic embedding generation for all documentation
Vector Search: Semantic search using vector similarity
LLM Integration: Self hosting open source models for optimal TTFT (time to first token) and TPS (tokens per second), along with uptime
Context Management: Maintains conversation context for follow-up questions
AI Search Optimization
- Embedding Lifecycle: Regenerate embeddings when MDX content or versions change.
- Chunking: Split long docs into semantic segments (~500 tokens) for efficient retrieval.
- Response Caching: Store frequently asked LLM answers in Redis with short TTLs.
Figure 3: Mintlify Rag Pipeline

Incremental Static Regeneration (ISR)
Based on assumptions, Mintlify most likely leverages Next.js ISR to bridge static and dynamic rendering, with Vercel's CDN optimizing ISR by caching pre-rendered pages at edge nodes and refreshing specific sections when updates are triggered.
Benefits:
Performance: Fast initial page loads from static cache
Freshness: Content updates without full site rebuilds
Scalability: Reduced server load through intelligent caching