Problem Statement & Motivation
The Gap in Existing Security
- Ground-based cameras and security personnel are often limited by line-of-sight, blind spots, and fixed vantage points.
- In large public gatherings or politically charged events, threats can emerge suddenly, and response times are critical.
- What if we could supplement human security with real-time aerial intelligence—drones that act as an extra set of sensory “eyes in the sky”?
Why Drone + AI?
- Consumer drones (e.g. DJI models) have become affordable, portable, and relatively capable in terms of video capture and control.
- Pairing them with AI opens the possibility for automated threat detection, scene understanding, and alerting.
- The goal is augmentation—not replacement: providing early warning, alerting human operators, and supporting situational awareness.
The vision
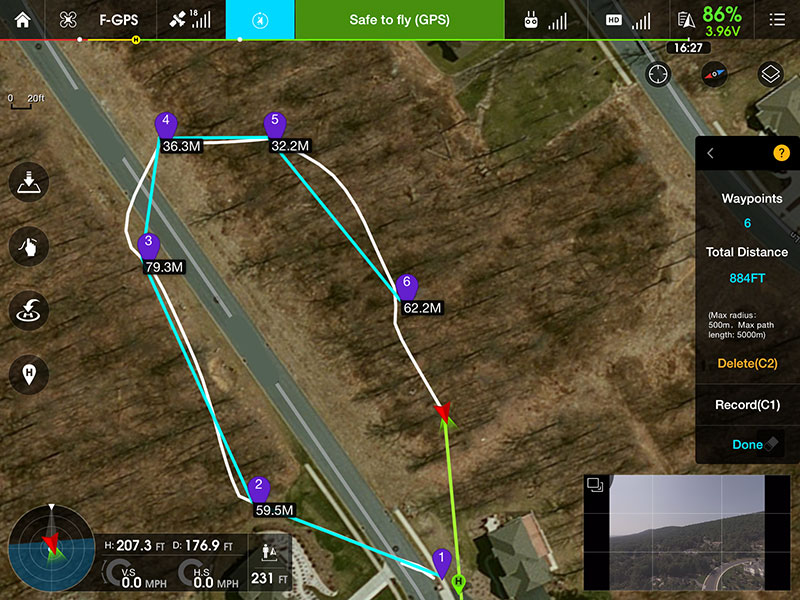
Going into building this, my idea was, that companies that host large outdoor events would use this with an arsenal (or just one) of consumer drones They ideally would do this with Waypoints which can be added to most DJI drones, or using 3rd party software apps like Litchi
Currently, in its current form, im not too sure how well it would do in production, for a couple reasons, stated later. But like anything, could be improved
First off, what is an RTMP Server?
RTMP stands for Real-Time Messaging Protocol. It is a TCP-based protocol developed by Macromedia (Adobe) in 2002 to stream audio, video, and data over the internet.
The primary role of RTMP was to enable the smooth transmission of increased amounts of data, which was needed to play video on Adobe’s Flash Player. While Flash turned obsolete at the end of 2020, RTMP continues to be used as an open-source protocol for first-mile contribution (from an encoder to an online video host), accepted by most streaming providers and encoders.
The big advantage of RTMP is that it maintains a persistent TCP connection between the video player and the server, delivering a reliable stream to the end-user.
Why Did I choose this protocol?
Because its what my DJI drone comes out of the box with. Thats literally it.
How normal RTMP servers operate
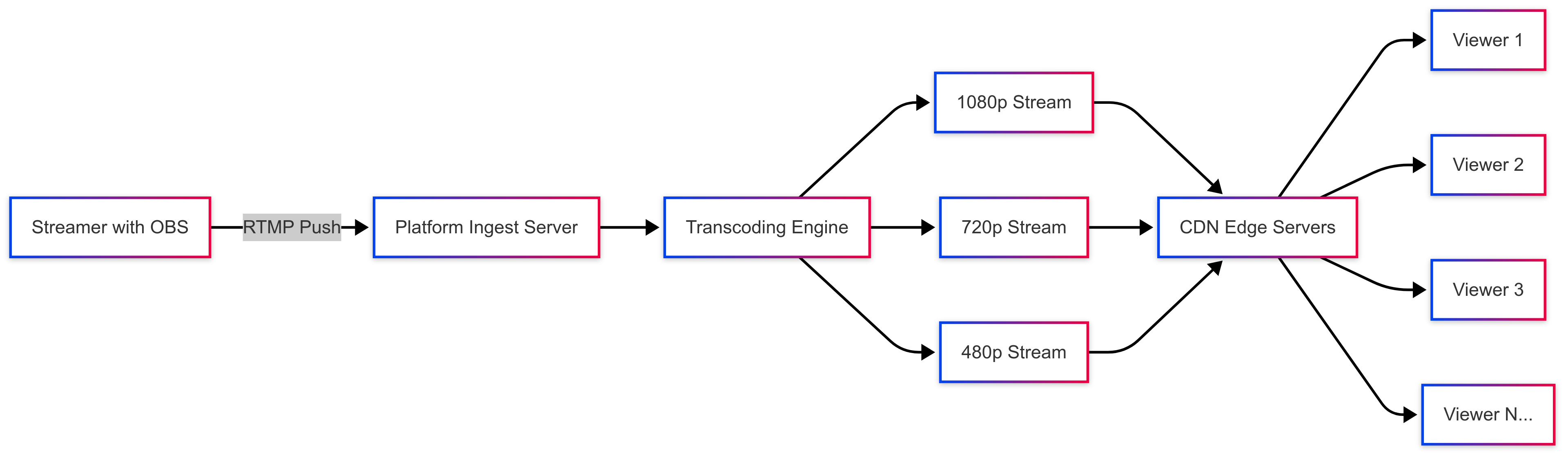
How the Raspberry Pi Aerial Intelligence Server works

System Architecture Overview
High-Level Data Flow
Drone video → RTMP ingestion → Frame capture → Pattern-based detector → Florence-2 analysis → Fusion logic → Alert / UI / loggingRTMP Ingestion & Frame Capture
- The system accepts incoming RTMP streams (e.g.,
rtmp://…/live/{stream_key}), allowing drones or OBS-like setups to push video. - Frames are sampled at a configurable rate (e.g. 1 fps or adjustable) to balance compute cost vs responsiveness.
Raspberry Pi Server Interface
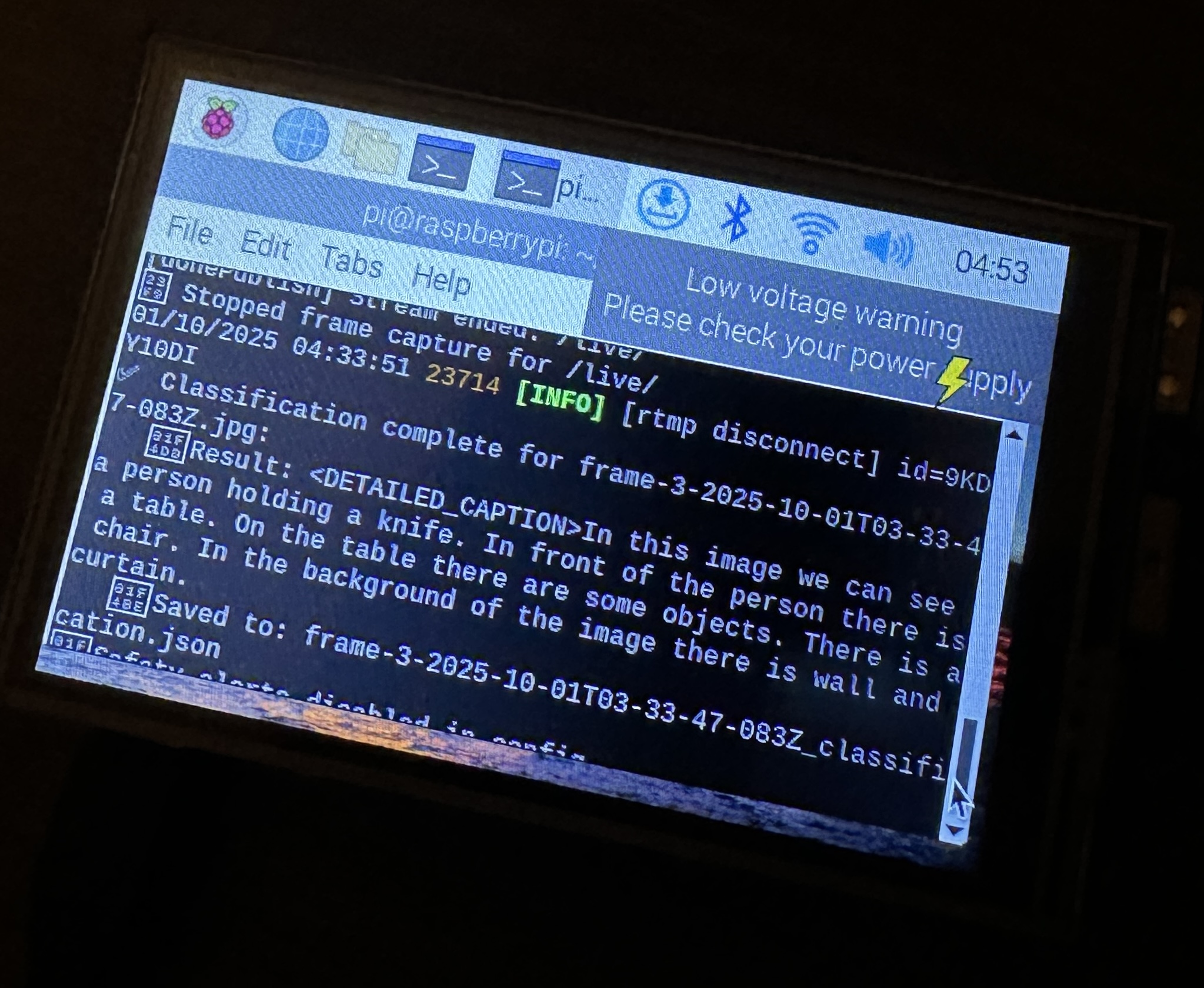
Here it saw me sitting on my desk holding a knife, which then it saved the image and sent it to me alerting the threat
Pattern-Based Threat Detector
- This component encodes predefined threat rules and object classes (weapons, fire, intrusion, masked persons, etc.).
- It assigns a preliminary severity (CRITICAL, HIGH, MEDIUM, LOW) based on detection confidence and heuristics.
- Because it’s rule-based it executes with minimal latency.
Here is an example of the prompt:
buildSecurityPrompt(classification) {
return `<MORE_DETAILED_CAPTION>Analyze this scene for security threats and suspicious activities.
Original description: "${classification}"
Please evaluate:
1. Are there any people in unauthorized areas?
2. Is anyone exhibiting suspicious behavior (hiding, breaking in, carrying weapons)?
3. Are there signs of vandalism, theft, or property damage?
4. Is this activity normal for this type of location?
5. What is the overall threat level (NONE/LOW/MEDIUM/HIGH/CRITICAL)?
Respond with: THREAT_LEVEL: [level] | CONFIDENCE: [0-100] | REASON: [brief explanation]`;
}
Why use pattern detection? It acts as a first-pass filter: fast, low-latency, and effective for clear, unambiguous detections. It helps avoid sending every frame to the heavier AI pipeline, or larger Model
AI Contextual Analysis with Florence-2
- The captured frame is fed into the Florence-2 model (via NVIDIA’s NIM APIs) for higher-level reasoning.
- Florence-2 is a vision-language foundation model that can interpret scenes, perform object detection, captioning, segmentation, and region reasoning. (build.nvidia.com)
- It takes a prompt or query (e.g. “Are there suspicious objects or unusual behaviors?”) and outputs reasoning, confidence, and classification in text form.
- This analysis supports detection of contextually suspicious situations (e.g. someone loitering, carrying concealed items, etc.).
Why Florence-2 / vision-language models?
- Unified reasoning: One model handles multiple tasks (detection, captioning, context) rather than requiring separate models. (Microsoft)
- Prompt-driven flexibility: You can direct it with different prompts to adapt to changing security needs.
- Compact size: Florence-2 comes in sub-billion parameter variants (0.23B and 0.77B) and is intentionally lightweight for real-world deployment. (Roboflow Blog)
That said, inference cost is nontrivial, and latency needs careful management.
Fusion & Decision Logic
- This stage combines signals from the pattern detector and the Florence-2 analysis.
- Logic includes thresholding (only escalate when severity or confidence exceed configured levels), temporal smoothing (e.g. consistent detection across frames), and suppression of redundant alerts.
- The architecture allows toggling “detailed analysis”, “notification threshold level”, and “time-of-day sensitivity” via configuration.
Why fusion? Neither pattern detection nor AI alone is sufficient. The fusion layer helps reduce false positives and increases robustness by requiring alignment across methods.
Alert Notification Service
-
Upon detection of a threat above threshold, this module sends notifications (e.g. via Telegram) with:
- Alert time
- Threat severity
- Confidence percentage
- Summary of scene (“In this image we see a person with a firearm…”)
- Suggested action and metadata
-
This can be extended to mobile push, email, dashboard popups, etc.
Challenges, Tradeoffs & Mitigations
Latency & Throughput
- AI inference introduces delay. Depending on hardware, each Florence-2 call can take hundreds of milliseconds or more. Right now, I am using the API, so I am not running the inference on the actual server itself, Nvidias servers are
That being said, becase they are open source models, I could technially run the model weights and inference on the mini computer, but, there would be a large increase in latency, and for what its worth, the API is not that expensive
- Mitigations:
- Asynchronous execution: pattern detection first, then AI.
- Batching / pipelining: queue frames, drop stale ones.
- Selectively disable heavy analysis during low-risk times.
Compute & Cost Constraints
- Running Florence-2 continuously at scale is resource-intensive.
- Options:
- Quantize model or use lower-precision inference
- Use edge devices (NVIDIA Jetson, etc.) for localized inference
False Positives / False Negatives
- Too many false alerts degrade operator trust; missing genuine threats is unacceptable.
- Mitigations:
- Use fusion logic and temporal smoothing
- Tune thresholds carefully based on real-world tests
- Add domain-specific fine-tuning or filtering
Privacy, Legal & Safety Considerations
- Drone-based surveillance is subject to aviation, privacy, and local laws.
- Safeguards:
- Restrict camera angles and zones
- Blurring or redacting faces if deployed widely
- Logging, accountability, and human in the loop for override
Connectivity & Robustness
- Drones streaming over wireless links can drop frames or lose connectivity.
- The system handles reconnects gracefully and continues pattern detection when AI is unreachable.
Adversarial & Spoofing Risks
- Attackers might try to trick AI models (camouflage, decoys, adversarial patches).
- Future work: adversarial defense, model robustness evaluation, fallback safe modes.
Why This Approach Beats Alternatives
- Single-model multi-mode vs multiple specialized models: Using Florence-2 unifies many vision tasks (detection, captioning, segmentation) into one prompt-driven model. (Microsoft)
- Hybrid pattern + AI delivers both speed (via pattern) and depth (via AI).
- Configurable thresholds & filtering allow safe operation in noisy real-world settings.
- Modular design means components (detector, model, notifier) can be upgraded separately.
Real-World Use Cases
- Public safety & crowd monitoring: Detect escalation early in protests, rallies, or festivals.
- Perimeter and intrusion detection: Patrol grounds, fences, construction sites, detect climbing or breach.
- Rapid threat detection in dynamic environments: Respond faster than static cameras.
- Supplement existing CCTV systems: Drones can cover blind spots and provide new vantage points.
Lessons Learned & Future Directions
Key Learnings
- Integrating a vision-language model into a real-time security pipeline taught me the art of balancing accuracy, latency, and resource constraints.
- The fusion approach is essential—neither pure AI nor rigid pattern systems are sufficient alone.
- Real-world robustness (connectivity drops, varying lighting, unexpected object motion) matters more than lab accuracy.
What’s Next
-
On-device inference / edge deployment Use Jetson or Orin-class devices to reduce latency and eliminate cloud dependency. (If I can get my hands on one)
-
Drone swarm coordination Multiple drones collaborating, sharing detections, and handing off monitoring zones using waypoints and automation
-
Geospatial mapping & overlay Combine GPS + camera calibration to project detections onto maps in real time.
-
Fine-tuning Florence-2 for security domain Train or adapt model on annotated datasets specific to crowd behavior, violence, weapons, etc.
-
Privacy-first features Face anonymization, restricted zones, human override, audit trails.
-
Adaptive sensitivity & learning System that adjusts thresholds based on historic false-positive feedback or environment context.